

A brief history of browser automation and why Browserbase can help you in todays environment

Recently I listened to Kenny Beats’ (“Whoa, Kenny!”) interview on Tetragrammaton. I’d recommend tuning in for many reasons, but it got me thinking about the ‘edges of the internet’. Shortly after, I thought about queuing for Glastonbury tickets, which got me thinking about.. browser automation.. and thus, this primer was born.
By ‘edges of the internet’, I mean places that you personally frequent that feel a little proprietary..? They’re earned. For me, that could be Factorio’s blog, PC’s fast list, or, perhaps, Polymarket’s Chess prop bets. Who ya got?
The problem with many of these ‘edges’ is that they’re often webpages, not webapps. You have to remember to visit ‘em, write ‘em down somewhere, parse them for the content you enjoy, etc. Or, even when they are webapps, you’re beholden to an API reference. What if you want access to data that an API doesn’t provide?
This is where scraping and browser automation (both of which we’ll dig into in detail) come in. Theoretically, with these two techniques, you can turn any web-page into a web-api. We’ll learn how later, by having a bit of fun and building our own HN tool.
It’s likely at this point that you’re thinking ‘isn’t scraping and browser automation old news?’. In short — yes. However, have you ever tried to build a durable web scraper? If not, just know that it’s not exactly trivial. Plus, Selenium kinda sucks.
There’s also a genuine opportunity to put LLMs to work here which we’ll dig into. Personally, I’m very excited about never having to write a line of .*(?!regex).* again. Whoa, Kenny! indeed.
Accordingly, I was happy to see Paul and the team at Browserbase taking things up a notch. Fwiw, I’ve been using Browserbase for weeks now and I’m a happy (paying!) customer. So, let’s see what all the fuss is about.
Ok, so, as discussed, we’ll learn about the evolution of scraping, browser automation, and Browserbase itself by building a Hacker News tool. It will:
Note 1: I’ll include the code I use so that folk can follow along, but you don’t need to fully grok the code itself. If you get stuck, or want more context, try throwing the code in your favourite LLM and asking some Qs.
Note 2: If you’re following along, I recommend using Flox to install the dependencies we use. It’ll keep your system clean & conflict free.
Whilst I was, correctly, far too occupied battling the Elite Four (iykyk) in the 1990s to care, I’m told that web scraping was pretty straightforward “back then”. Websites essentially looked like this: http://thegestalt.org/simon/ps2rant.html.
I.e. they were often walls of text with no real interactivity or client-side rendering. And yes, this post is the co-founder of Fastly complaining about the PS2. I did tell you, I spend far too much time on the internet.
Let’s see how we can scrape websites that look like this. Let’s first use cURL (fun fact: prev named httpget and urlget) to retrieve the webpage:
This is fine, but cURL doesn’t include any built-in text processing tools, so we have to use command line utilities like ‘grep’, ‘awk’ or ‘sed’ to process this data further. Par example, if we want to extract the URL’s included in Simon’s post we’d use ‘awk’:
‘awk’(ward) being the operative word here, this command is hard for me to interpret, and I wrote it yesterday.. things can get unwieldy, fast, if we want to do more complex text processing:
curl -s http://thegestalt.org/simon/ps2rant.html | \
sed -n 's/.*>\(.*\)<.*/\1/p' | \
tr '[:upper:]' '[:lower:]' | \
tr -c '[:alnum:]' '[\n*]' | \
awk 'NF' | \
sort | \
uniq -c | \
sort -nr | \
head -n 10
I’d more readily read Cuneiform! Let’s keep in mind however, that Simon’s webpage is very basic by modern standards (although I do like the recent vanilla html ‘comeback’). Brace yourselves, as you see what happens when we ‘cURL’ Hacker News:
Eugh! Modern webpages have a lot more going on. Also, it’s not like Hacker News is going to win a Webby anytime soon (sorry, PG); it’s still pretty basic. ‘BeautifulSoup’ and ‘Requests’ came along in 2004 and 2011 respectively to make parsing modern webpages like this a little easier.
Let’s use Requests (for making http requests) and BeautifulSoup (for html parsing) to visit the Hacker News page and extract every title on the front page as well as their corresponding hyperlinks. I’ll bold some functionality that I think is worth noting but, don’t fret if this code is confusing. I’ll elaborate on what’s important.
file name: hacker_news_bs4.py
------------------------------------------------------------------------
import requests
from bs4 import BeautifulSoup
from typing import List, Tuple
def scrape_hacker_news() -> List[Tuple[str, str]]:
# Base URL for Hacker News
url = "https://news.ycombinator.com/"
# Send GET request
response = requests.get(url)
# Parse HTML content
soup = BeautifulSoup(response.text, 'html.parser')
# Find all story titles (they are in 'titleline' class)
stories = []
# Find all story rows (they have class 'athing')
for story in soup.find_all('tr', class_='athing'):
# Find the title span
titleline = story.find('span', class_='titleline')
if titleline:
# Get the first link in the titleline
link_tag = titleline.find('a')
if link_tag:
title = link_tag.get_text()
# Get href attribute, if it's a relative URL, prepend the base URL
link = link_tag.get('href')
if link.startswith('item?'):
link = url + link
stories.append((title, link))
return stories
def main():
try:
stories = scrape_hacker_news()
# Print the results
print(f"Found {len(stories)} stories:\n")
for i, (title, link) in enumerate(stories, 1):
print(f"{i}. {title}")
print(f" Link: {link}\n")
except Exception as e:
print(f"An error occurred: {e}")
if __name__ == "__main__":
main()
If this is your first time looking at BeautifulSoup it may look a little overwhelming; the most important item to note is that the library gives you tools (or functions) like ‘.find_all( )’ or ‘.get_text( )’ that can search for html like anchor tags or specific CSS class names like ‘athing’. These libraries ultimately make parsing webpages a hell’uva lot easier.
Let’s see what our HN code returns when we run the above script:
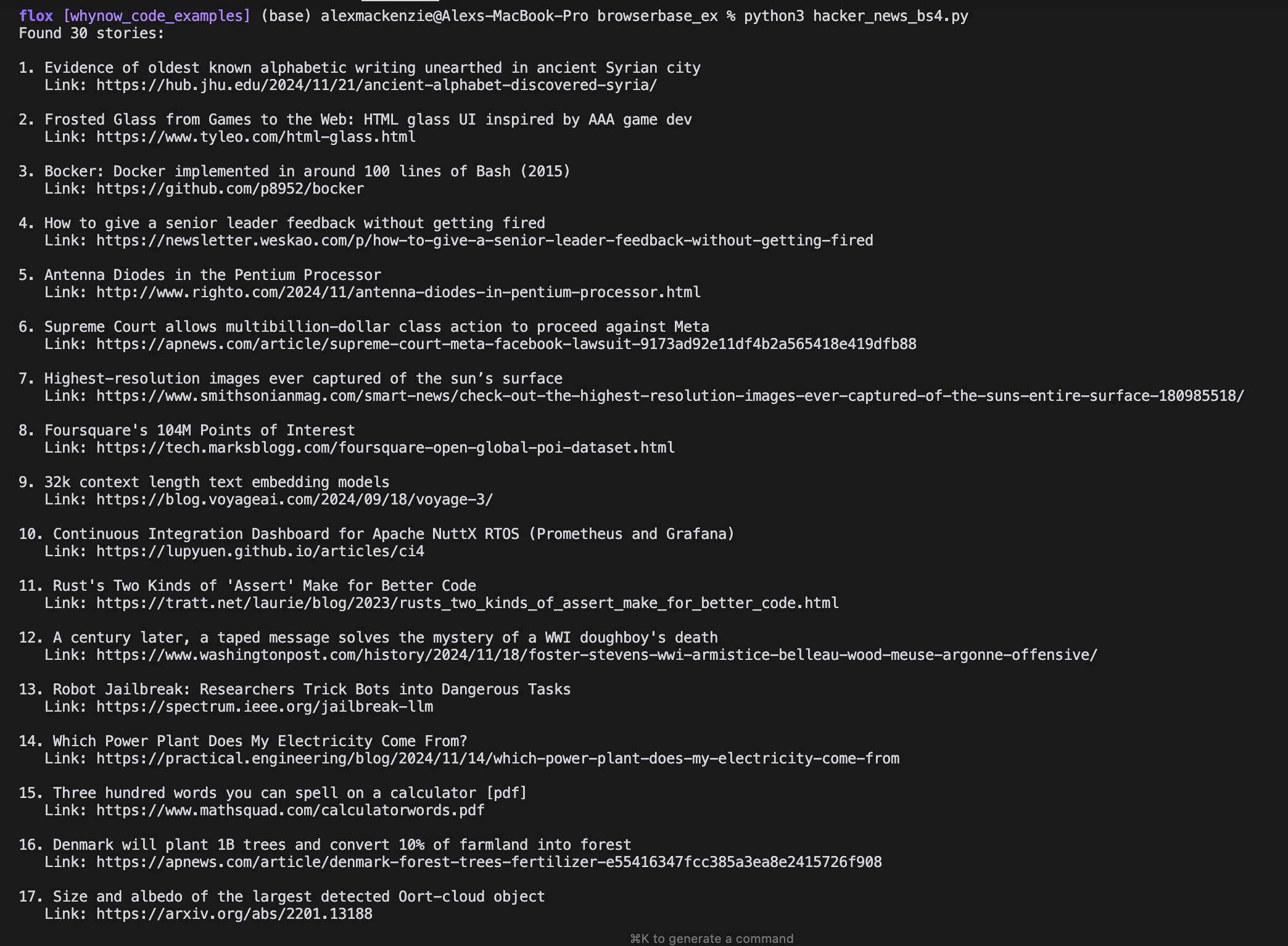
Nice, we’ve made progress here (Bocker looks cool). But remember, we also want to ‘click’ into the hyperlink of each post. We can technically do this with BeautifulSoup and Requests, but we’ll likely run into some difficulties which I’ll outline in the next section below.

With the advent of JavaScript (which I wrote about in my primer on Deno), came the ‘dynamic’ webpage. JavaScript enables websites to render, and/or change, ‘client-side’ (i.e. on a user’s device) vs. on a server.
Celtic and Rangers fans are more likely to ‘get on’ than those debating the pros/cons of client-side rendering, so let’s not get into the weeds here. Instead, let’s understand why client-side rendering spoiled our (Beautiful)Soup via an example.
Recently, I tried to scrape the Public Comps (non-gated) dashboard using Requests and BeautifulSoup. When you do so, you receive a bunch of HTML (mainly just SVG coordinates), but no company data. Visit the site, and have a guess why this may be?
Go on. Visit it.
This data is rendered client-side! How this webpage likely works is that when it’s first loaded, a basic HTML skeleton is rendered. Then, the webpage itself will make an API call (or ‘fetch’) the underlying data that populates the corresponding charts. The issue with BeautifulSoup & Requests is that it:
I’m sure many of the links returned by our HN scraper will act similarly to Public Comps, and so, we need an alternative approach. Something more.. robust. Along Came Browser Automation.
Let’s take a step back for a second. When we’re using the Google Chrome ‘app’ ourselves, we don’t run into any of the above issues, right? Cool animations run, buttons can be clicked, images are downloadable, et cetera.
We ‘control’ this Google Chrome app with our mouse and keyboard and all works swimmingly. So, what if we could control this same app, but with code? This was Jason Huggins’ core idea with Selenium back in 2004.
Let’s build our HN tool using Selenium this time. Remember, I think ‘Selenium kinda sucks’. I won’t share my Selenium code (it will overcomplicate things), but I will share snippets that’ll highlight its flaws. But first, proof that Selenium can get the job done:
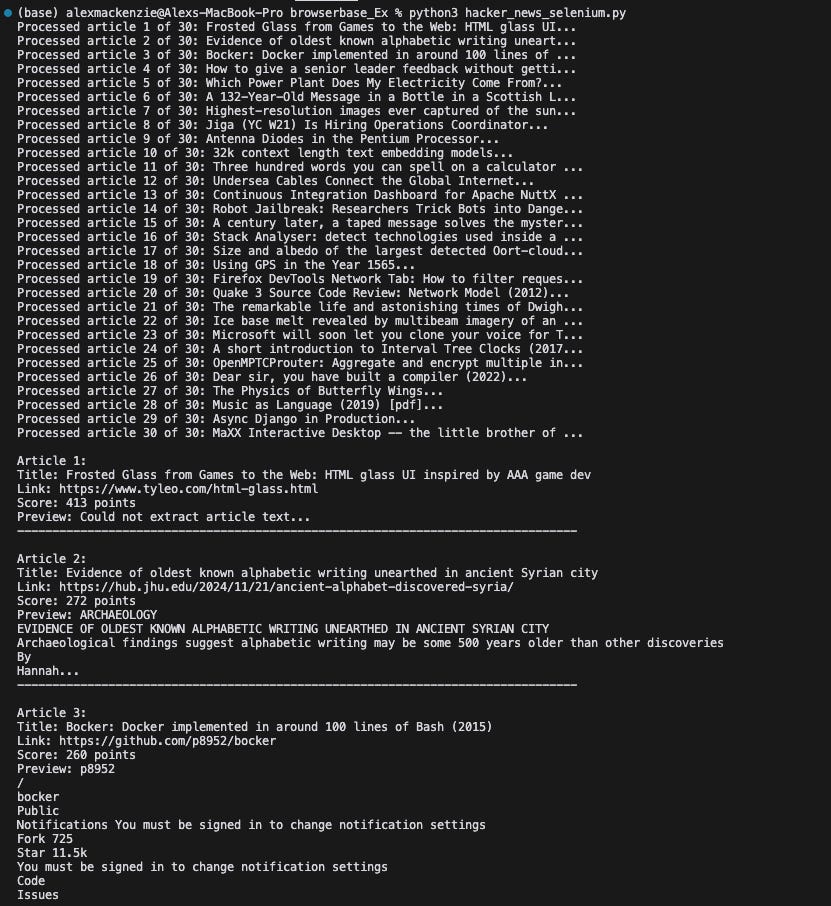
Ok, so what's the issue with Selenium? Well, firstly, look at the extensive set of dependencies and complex config it requires:
# There's a bunch of 'scaffolding' that needs to be imported
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException
import time
import json
# Configures the Chrome web driver
def setup_driver():
options = Options()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--window-size=1920,1080')
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
No! Again! Cursor (see my primer here if interested) has made my life so much easier now, but I used to spend hours getting this set-up right. This used to take all of the fun out of building scrapers. I guess this has changed now..
..what hasn’t changed, however, is how ‘brittle’ Selenium’s CSS selectors are. You might recall that our HN scraper looks for the CSS class called “athing”; this is fine, until the developers of HN decide to change their class naming conventions. If this class changes, and is now called “athing2”, our entire scraper breaks. No bueno.
There’s a plurality (minimal CAPTCHA support, high resource usage, memory leaks) of other small issues that add up to make the maintenance of a Selenium script a bit of a nightmare. Hopefully, you’ve built a sense for why we might want something a little different? Some names such as Playwright, Puppeteer and, now, Browserbase, came along to help us all out.

Ok. So, what is Browserbase? Let’s go with their definition which we’ll then break down in our own way:
‘Browserbase offers a reliable, high performance serverless developer platform to run, manage, and monitor headless browsers at scale. Leverage our infrastructure to power your web automation and AI agents.’
Let’s start with what is likely Browserbase’s most experimental (yet profound) feature, Stagehand. I’ve always liked Josh Wolfe’s framing of ‘following directional arrows of progress’; in browser automation’s case, we’ve been trending towards selecting html and/or css elements via natural language for years.
Why? Well, the end goal has always been to get your code to ‘click the log-in button’, but until LLMs, we had to use weak proxies such as: ‘page.click(".login-button")’ to do so. No longer. How so?
Well, at a (very) high-level, Stagehand consists of two functions: ‘act( )’ and ‘extract( )’.
‘act( )’ allows Stagehand to interact with a webpage. If we visit End Clothing, we could provide the act function with some natural language like ‘act(“search for Palace hats”)’ or ‘act(“click on the first shoe”)’ & Stagehand will dynamically generate the underlying Playwright code to get the job done. I cannot stress enough how cool this is.
‘extract( )’ does what you’d likely expect.. it grabs structured text from the webpage. Par example, we could ‘extract(“the price of the first shoe”)’ or ‘extract(“the navbar”)’. Hopefully, you’re starting to see how leveraging natural language makes our browser automation much more robust, or, reliable (see definition above). Let’s see if these functions enable us to build our HN tool in its final form?:

There ya have it. Our Hacker News Daily Summary email. Nice one Browserbase.
Browserbase does a lot more on the reliability front though. Remember, most sites don’t like browser automation, or, ‘bots’, so they’re constantly trying to thwart our efforts. Boo! To combat bots, websites will try and ‘fingerprint’ (i.e. record and recognise) your device by tracking attributes such as your: browser version, IP address, website activity, etc. It’s really quite smart.
So, how do we fight back? We won’t dig into everything Browserbase does, but I think it’s worth understanding ‘residential proxies’ as one arrow in our quiver. As noted, one way to spot-a-bot is to track IP addresses. If a given IP address consistently interacts with a site in some predictable manner, at a predictable interval, the site may block its access or throw a CAPTCHA at it.
So, logically, one way to fight back is to not use our own IP address, but instead, route our request through another server (or, ‘proxy’) to mask our presence. The ‘top grade’ of proxy servers is a ‘residential proxy’, which is a legitimate device (think a personal computer or router) that belongs to an actual household. Browserbase enables us to tap into a configurable network of these proxies. Pretty sweet.
Alright, let’s dig into Browserbase’s developer platform and then we’ll wrap up. And before you say it.. I know my product screenshots don’t exactly look like Linear’s.. but hey, I guess my writing is ok.
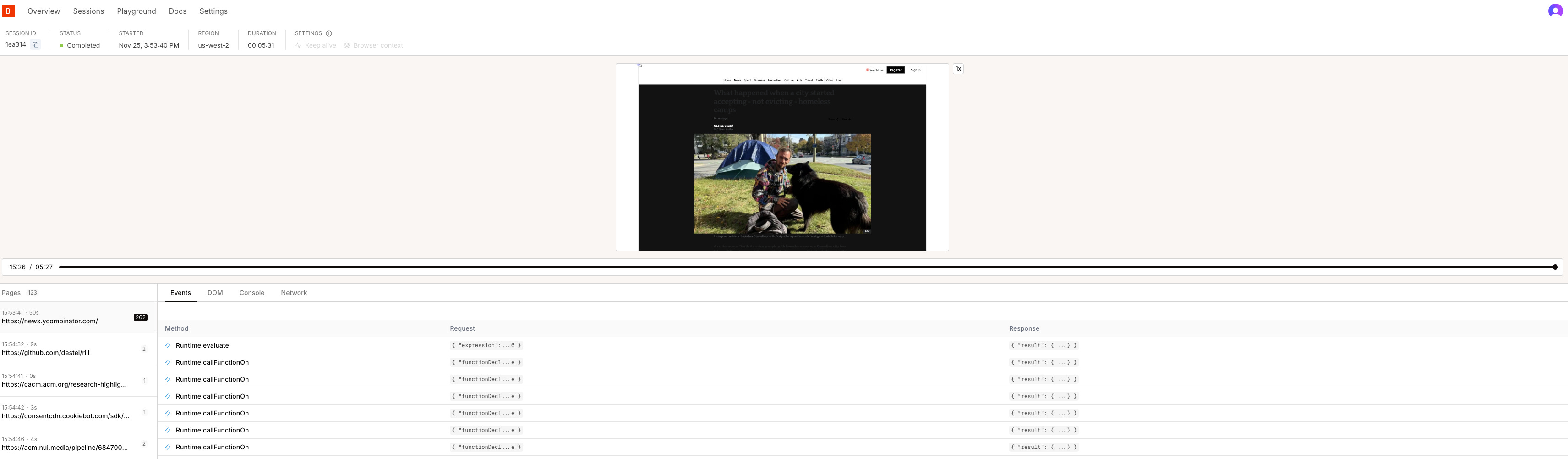
So, what you’re seeing above is where the action is — Browserbase’s ‘Sessions’ tab. Each time we run a browser automation with Browserbase we get a full play-by-play of what happens.
For each ‘session’ (i.e. each time we run our script) we can see: what pages we visit, the page’s corresponding ‘DOM’ (or ‘document object model’), the network requests (e.g. API calls) a given website makes, etc. This is super helpful for understanding exactly what our scraper is doing, as well as for debugging any reliability or performance issues. Finally, browser automation has a modern developer experience!
And that's a wrap! I would encourage you all to visit your own ‘corner of the internet’ and ask yourself, could I turn this into an API? If so, fire away and let me know what you think of Flox, Northflank, and, of course, Browserbase.
Thank you all for reading, I have a tonne of fun writing these.